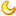|
|
// 预计存入 1w 条数据,初始化赋值 10000,避免 resize。
HashMap<String,String> map = new HashMap<>(10000)
// for (int i = 0; i < 10000; i++)
Java 集合的扩容
HashMap 算是我们最常用的集合之一,虽然对于 Android 开发者,Google 官方推荐了更省内存的 SparseArray 和 ArrayMap,但是 HashMap 依然是最常用的。
我们通过 HashMap 来存储 Key-Value 这种键值对形式的数据,其内部通过哈希表,让存取效率最好时可以达到 O(1),而又因为可能存在的 Hash 冲突,引入了链表和红黑树的结构,让效率最差也差不过 O(logn)。
整体来说,HashMap 作为一款工业级的哈希表结构,效率还是有保障的。
编程语言提供的集合类,虽然底层还是基于数组、链表这种最基本的数据结构,但是和我们直接使用数组不同,集合在容量不足时,会触发动态扩容来保证有足够的空间存储数据。
动态扩容,涉及到数据的拷贝,是一种「较重」的操作。那如果能够提前确定集合将要存储的数据量范围,就可以通过构造方法,指定集合的初始容量,来保证接下来的操作中,不至于触发动态扩容。
这就引入了本文开篇的问题,如果使用 HashMap,当初始化是构造函数指定 1w 时,后续我们立即存入 1w 条数据,是否符合与其不会触发扩容呢?
在分析这个问题前,那我们先来看看,HashMap 初始化时,指定初始容量值都做了什么?
PS:本文所涉及代码,均以 JDK 1.8 中 HashMap 的源码举例。
HashMap 的初始化
在 HashMap 中,提供了一个指定初始容量的构造方法 HashMap(int initialCapacity),这个方法最终会调用到 HashMap 另一个构造方法,其中的参数 loadFactor 就是默认值 0.75f。
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
其中的成员变量 threshold 就是用来存储,触发 HashMap 扩容的阀值,也就是说,当 HashMap 存储的数据量达到 threshold 时,就会触发扩容。
从构造方法的逻辑可以看出,HashMap 并不是直接使用外部传递进来的 initialCapacity,而是经过了 tableSizeFor() 方法的处理,再赋值到 threshole 上。
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
在 tableSizeFor() 方法中,通过逐步位运算,就可以让返回值,保持在 2 的 N 次幂。以方便在扩容的时候,快速计算数据在扩容后的新表中的位置。
那么当我们从外部传递进来 1w 时,实际上经过 tableSizeFor() 方法处理之后,就会变成 2 的 14 次幂 16384,再算上负载因子 0.75f,实际在不触发扩容的前提下,可存储的数据容量是 12288(16384 * 0.75f)。
这种场景下,用来存放 1w 条数据,绰绰有余了,并不会触发我们猜想的扩容。
HashMap 的 table 初始化
当我们把初始容量,调整到 1000 时,情况又不一样了,具体情况具体分析。
再回到 HashMap 的构造方法,threshold 为扩容的阀值,在构造方法中由 tableSizeFor() 方法调整后直接赋值,所以在构造 HashMap 时,如果传递 1000,threshold 调整后的值确实是 1024,但 HashMap 并不直接使用它。
仔细想想就会知道,初始化时决定了 threshold 值,但其装载因子(loadFactor)并没有参与运算,那在后面具体逻辑的时候,HashMap 是如何处理的呢?
在 HashMap 中,所有的数据,都是通过成员变量 table 数组来存储的,在 JDK 1.7 和 1.8 中虽然 table 的类型有所不同,但是数组这种基本结构并没有变化。那么 table、threshold、loadFactor 三者之间的关系,就是:
table.size == threshold * loadFactor
那这个 table 是在什么时候初始化的呢?这就要说会到我们一直在回避的问题,HashMap 的扩容。
在 HashMap 中,动态扩容的逻辑在 resize() 方法中。这个方法不仅仅承担了 table 的扩容,它还承担了 table 的初始化。
当我们首次调用 HashMap 的 put() 方法存数据时,如果发现 table 为 null,则会调用 resize() 去初始化 table,具体逻辑在 putVal() 方法中。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length; // 调用 resize()
// ...
}
在 resize() 方法中,调整了最终 threshold 值,以及完成了 table 的初始化。
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1;
}
else if (oldThr > 0)
newCap = oldThr; // ①
else {
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
// ②
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr; // ③
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab; // ④
// ....
}
注意看代码中的注释标记。因为 resize() 还糅合了动态扩容的逻辑,所以我将初始化 table 的逻辑用注释标记出来了。其中 xxxCap 和 xxxThr 分别对应了 table 的容量和动态扩容的阀值,所以存在旧和新两组数据。
当我们指定了初始容量,且 table 未被初始化时,oldThr 就不为 0,则会走到代码 ① 的逻辑。在其中将 newCap 赋值为 oldThr,也就是新创建的 table 会是我们构造的 HashMap 时指定的容量值。
之后会进入代码 ② 的逻辑,其中就通过装载因子(loadFactor)调整了新的阀值(newThr),当然这里也做了一些限制需要让 newThr 在一个合法的范围内。
在代码 ③ 中,将使用 loadFactor 调整后的阀值,重新保存到 threshold 中。并通过 newCap 创建新的数组,将其指定到 table 上,完成 table 的初始化(代码 ④)。
到这里也就清楚了,虽然我们在初始化时,传递进来的 initialCapacity 虽然被赋值给 threshold,但是它实际是 table 的尺寸,并且最终会通过 loadFactor 重新调整 threshold。
那么回到之前的问题就有答案了,虽然 HashMap 初始容量指定为 1000,但是它只是表示 table 数组为 1000,扩容的重要依据扩容阀值会在 resize() 中调整为 768(1024 * 0.75)。
它是不足以承载 1000 条数据的,最终在存够 1k 条数据之前,还会触发一次动态扩容。
通常在初始化 HashMap 时,初始容量都是根据业务来的,而不会是一个固定值,为此我们需要有一个特殊处理的方式,就是将预期的初始容量,再除以 HashMap 的装载因子,默认时就是除以 0.75。
例如想要用 HashMap 存放 1k 条数据,应该设置 1000 / 0.75,实际传递进去的值是 1333,然后会被 tableSizeFor() 方法调整到 2048,足够存储数据而不会触发扩容。
当想用 HashMap 存放 1w 条数据时,依然设置 10000 / 0.75,实际传递进去的值是 13333,会被调整到 16384,和我们直接传递 10000 效果是一样的。
小结时刻
到这里,就了解清楚了 HashMap 的初始容量,应该如何科学的计算,本质上你传递进去的值可能并无法直接存储这么多数据,会有一个动态调整的过程。其中就需要将我们预期的值进行放大,比较科学的就是依据装载因子进行放大。
最后我们再总结一下:
- HashMap 构造方法传递的 initialCapacity,虽然在处理后被存入了 loadFactor 中,但它实际表示 table 的容量。
- 构造方法传递的 initialCapacity,最终会被 tableSizeFor() 方法动态调整为 2 的 N 次幂,以方便在扩容的时候,计算数据在 newTable 中的位置。
- 如果设置了 table 的初始容量,会在初始化 table 时,将扩容阀值 threshold 重新调整为 table.size * loadFactor。
- HashMap 是否扩容,由 threshold 决定,而 threshold 又由初始容量和 loadFactor 决定。
- 如果我们预先知道 HashMap 数据量范围,可以预设 HashMap 的容量值来提升效率,但是需要注意要考虑装载因子的影响,才能保证不会触发预期之外的动态扩容。
HashMap 作为 Java 最常用的集合之一,市面上优秀的文章很多,但是很少有人从初始容量的角度来分析其中的逻辑,而初始容量又是集合中比较实际的优化点。其实不少人也搞不清楚,在设置 HashMap 初始容量时,是否应该考虑装载因子,才有了此文。
如果本文对你有所帮助,留言、转发、点赞是最大的支持,谢谢!
<hr>在头条号私信我。我会送你一些我整理的学习资料,包含:Android反编译、算法、设计模式、虚拟机、Linux、Kotlin、Python、爬虫、Web项目源码。
|
|




 发表于 2021-2-17 21:21:43
发表于 2021-2-17 21:21:43